在剛過去的2023年,運維圈發生了不少令人矚目的事件,尤其在年末各互聯網大廠猶如在玩一個“蘿卜蹲”的游戲,一個接一個地爆發了各種黑天鵝事件,造成了極大的影響。因此應急災備管理的建設與重要價值再一次在運維圈熱烈討論了起來,本篇我們將著重針對企業的信息系統應急關鍵業務流程和活動進行詳細說明。
01. 信息系統應急災備管理的關鍵業務價值流
說到信息系統應急的業務價值流,其實非常簡單,就是“事前——事中——事后”,即“故障事前預防——故障事中調度——故障事后改進”三個環節,讓人很容易聯想到消防演練和消防救援的關系,沒錯,就是這么簡單的邏輯,如下圖所示:

通過上圖可以總結出 ,如果事前我們沒有做好充足的準備工作,不進行常態化的演練;如果對事故采取一種得過且過的態度,缺乏深入分析和必要的應急能力,事故發生時,就會手足無措,當火勢進一步蔓延,導致財產更大的損失。相反,如果我們做好充足的預防,針對每一次演練及故障詳細分析、反思與總結,才能讓組織具備完善的應急能力,在故障發生時就會做到快速控制火勢蔓延,舉重若輕,了然于胸。
02. 信息系統應急災備管理的活動
站在應急管理的視角來看:
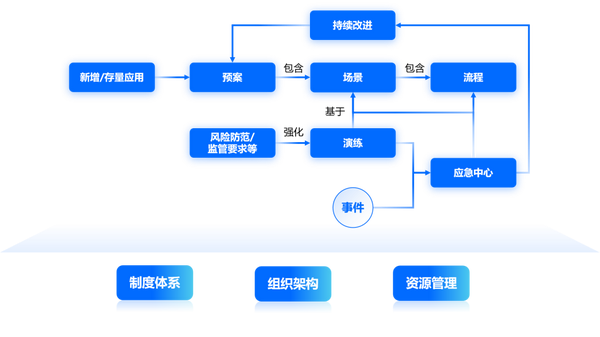
通過以上兩層架構我們可以看到,應急的建設底座需要建設相應的管理規范和組織能力,同時確保信息系統的底層IaaS支持相關的應急或災備活動,本次我們暫且不談;詳細聊一聊上層的各種對象,并沿著用戶旅程觀察所開展的具體活動。
1)故障事前預防
① 預案及場景的梳理及建設
實現應急預案及場景的線上建設,審批發布、跟蹤、留痕等管理,解決應急預案及場景分散在各運維人員手中無統一歸檔、版本不一致等問題。
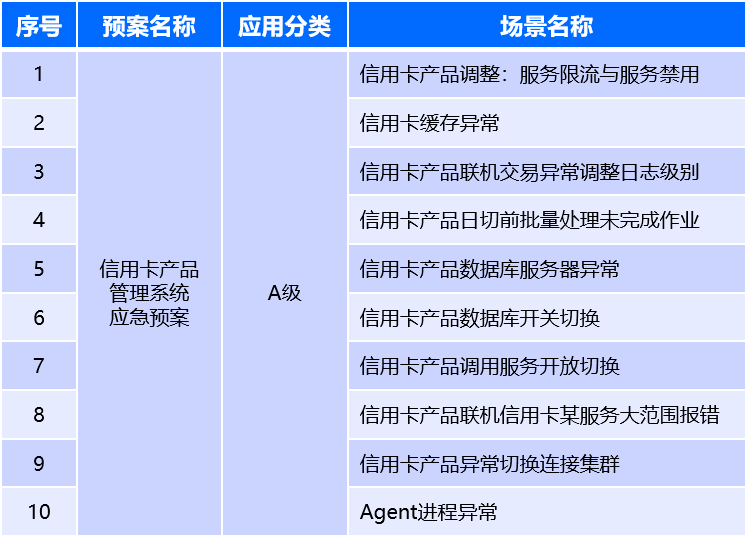
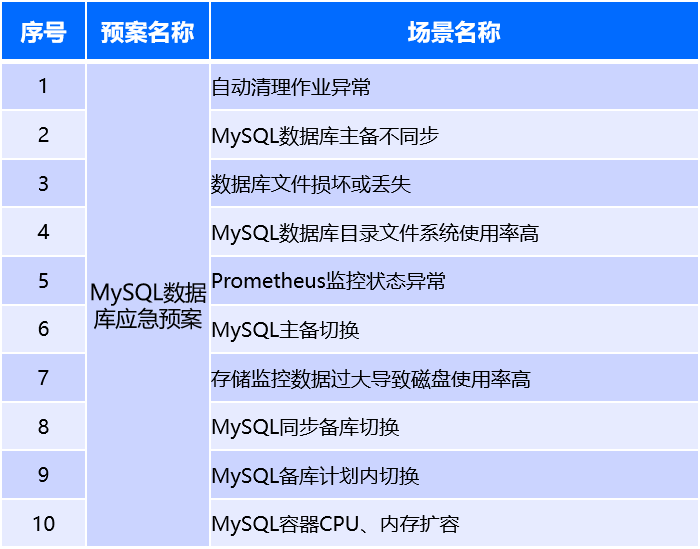
針對不同企業內部的應急組織,預案及場景大多情況下分為“業務線”“和“專業線”進行管理,對應企業內部的應用運維組和基礎架構組等情況,因此在建設預案及場景的活動時,不僅需要考慮不同類型記錄的相關要素,也需要進行權限控制。
② 自動化流程的編排
針對不同的場景,除了制定相應的處置流程,還可以制定業務驗證流程,在應急演練和任務執行時,驗證自動化的可用性。
③ 應急演練
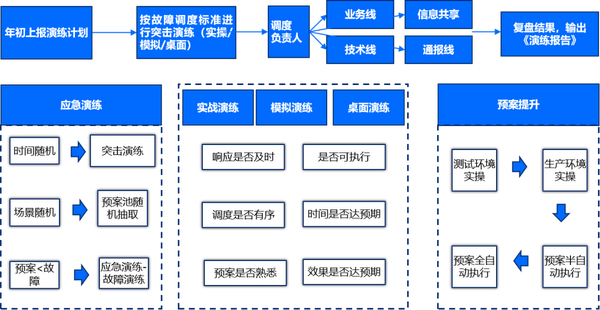
為了讓所有的應急成員能夠更好地掌握應急知識,讓預案及場景長效保鮮,需要通過不同的形式進行常態化演練。應急用戶在平臺上上報演練計劃,并經過審批,在相應演練窗口進行實戰演練/模擬演練/桌面演練,隨著演練場景的成熟,用戶可通過混沌工程、無損演練的方式,挖掘信息系統可能存在的風險,提高系統的健壯性與穩定性。
2)故障事中調度
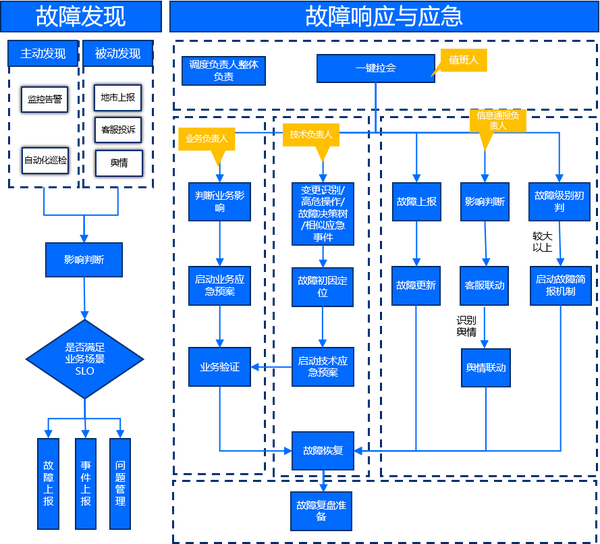
① 故障發現
通過可觀測體系及時地發現系統故障,同時也為業務提供反饋渠道。
② 應急響應
通過應急管理平臺頁面發現有異常事件,確認業務影響范圍,并通過多維數據的匯聚和統計進行分析,多維數據涵蓋近期是否有相關業務的變更,是否有高危操作,是否有歷史相同類似應急場景,并立即進行一次業務的健康性檢查,最終確定是否為應急事件并啟動應急流程。
③ 應急會商
根據影響的業務及范圍,通過應急組織或其他不同職責劃分,選取應急處置人員,多渠道在線即時IM溝通,反饋問題及處置意見,解決在應急組織過程中信息通知、共享方式分散的問題。
④ 應急決策
根據啟動的應急事件所展示的故障特征,啟動依據等要素,快速判斷是否有應急場景及自動化處置流程與之匹配,如有,則快速執行,驗證業務可用性;若沒有,則需快速討論出手動恢復方案,并確定處置風險進行故障上報。
⑤ 應急通告
在故障處置環節,需要定期以故障簡報機制定時反饋故障應急進展,直到故障完全恢復,同步確定是否需要進行輿情聯動,并進行故障復盤準備。
3)故障事后改進
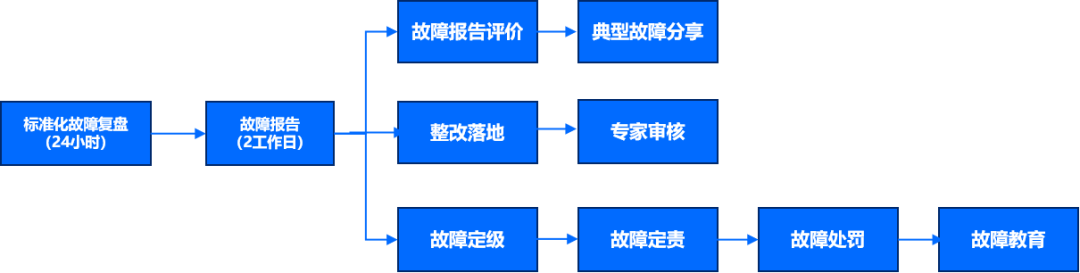
① 故障復盤
故障應急結束后,應當在最短時間內對故障根因、測試過程、變更過程和應急過程進行復盤,并列出改進建議,持續跟蹤。例如故障定級,處置時間的長短等因素可能決定了故障的影響面和影響范圍,如果處置足夠快,可以允許故障等級降低級別,即故障等級低于事件等級,反之也可以提高故障等級。
故障復盤應盡量實現不再發生此故障,如因架構問題無法短時間內解決時,應保證遇到問題能夠快速恢復。在復盤及整改過程中,通過應急過程的快照,詳細回溯處理過程,多層次分析原因,統計可以量化的業務影響,最終制定優化措施并再次交由專家評審。
② 培訓管理
建立完善的線上培訓通知、執行、考核機制,實現應急組織全員的技能持續提升。
③ 持續運營
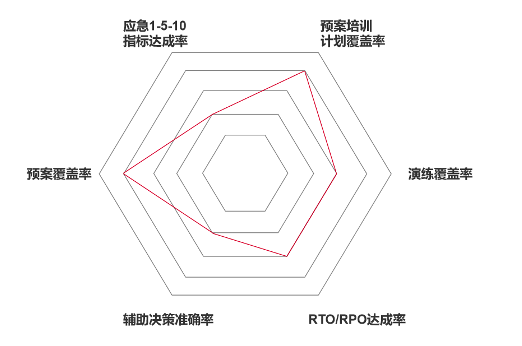
結合信息系統平臺的演練、應急處置等多方面情況,進行能力評估。企業應當設置不同維度的應急運營指標,定期組織開展應急能力評估,發掘故障應急的薄弱環節,集中力量,針對性地改善、提高應急能力。
應急管理是一個融合了配置、觀測、執行、流程、智能分析技術能力、管理規范、組織能力的綜合體系。
以上,就是針對整個應急體系全生命周期總結的價值流及價值流中的核心活動,希望每個企業都能夠將自己的應急能力提升得更加完善,不再發生業務中斷,更好地提供服務。











